Research by Topic
Graphical Models: Methods and Theory with Missing Data
High-dimensional graphical models have been a powerful tool for learning connections or interaction patterns among a large number of variables, with wide applications such as learning stock networks, social networks, etc. While most prior work focuses on the case when all variables are measured simultaneously, one typical challenge in real data sets is that only certain subsets of variables can be measured together, or can be measured sufficiently many times. To estimate the graph (conditional independence relationship) or certain characteristics of the graph accurately, novel statistical methods and theory need to be developed. I am actively working on this direction and happy to collaborate on related topics!
Papers:
Graphical Model Inference with Erosely Measured Data
Lili Zheng, Genevera I. Allen
Journal of the American Statistical Association, Theory and Methods
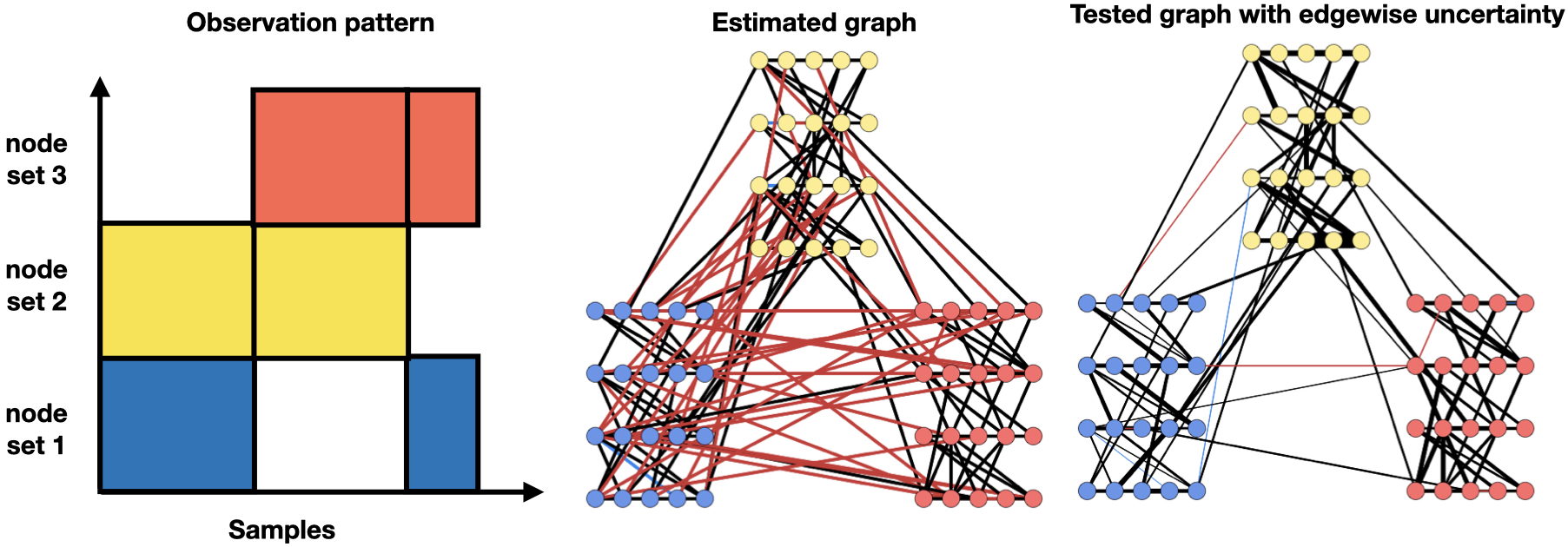
In this work, we are primarily concerned with graphical model inference from uneven and irregular measurements, which we term as ‘‘erose measurements". This is motivated by neuroscience and genetic data applications where the missingness can be highly uneven with drastically different sample sizes. In these scenarios, uncertainty quantification can be extremely important since some parts of the graph can be estimated with much higher confidence than the others. We propose GI-JOE (Graph Inference when Joint Observations are Erose) to perform edge-wise testing in this setting, where the uncertainty level of each edge depends on the sample size of the associated neighbors. Below is a illustrative example of how GI-JOE (tested graph on the right) improves graph selection by considering uneven uncertainties across the graph.
Nonparanormal Graph Quilting with Applications to Calcium Imaging
Andersen Chang*, Lili Zheng*, Gautam Dasarthy, Genevera I. Allen
STAT
Low-Rank Covariance Completion for Graph Quilting with Applications to Functional Connectivity
Andersen Chang, Lili Zheng, Genevera I. Allen
Learning Gaussian Graphical Models with Differing Pairwise Sample Sizes
Lili Zheng, Genevera I. Allen
International Conference on Acoustics, Speech, and Signal Processing (ICASSP). 2022
Interpretable Machine Learning
With machine learning models being implemented everywhere in modern life, making them interpretable and trustworthy is a crucial task for researchers from different domains. As a statistician, I am passionate about contributing to the challenging problems in interpretable machine learning through statistical lens, e.g., statistical theory and inference methods.
Papers:
Interpretable Machine Learning for Discovery: Statistical Challenges & Opportunities
Genevera I. Allen, Luqin Gan, Lili Zheng
Annual Review of Statistics and Its Application
Model-Agnostic Confidence Intervals for Feature Importance: A Fast and Powerful Approach Using Minipatch Ensembles
Luqin Gan*, Lili Zheng*, Genevera I. Allen
High-dimensional Networks Estimation in Time Series Models
High-dimensional autoregressive models can capture how the past eventsstatus associated with a huge collection of nodes influence their future eventsstatus, where the influence patterns can reveal underlying network structures. For example, the past firing of neurons may trigger or inhibit the future firings of their neighbors; past posts of a twitter user may also influence the likelihood of his/her followers to send new tweets. The influence network among these nodes can then be encoded by the high-dimensional autoregressive parameter. The estimation and testing problem for the underlying network structure imposes both methodological and theoretical challenges.
Papers:
Context-dependent self-exciting point processes: models, methods, and risk bounds in high dimensions
Lili Zheng, Garvesh Raskutti, Rebecca Willett, Benjamin Mark
Journal of Machine Learning Research. 2021 [Slides][Code]
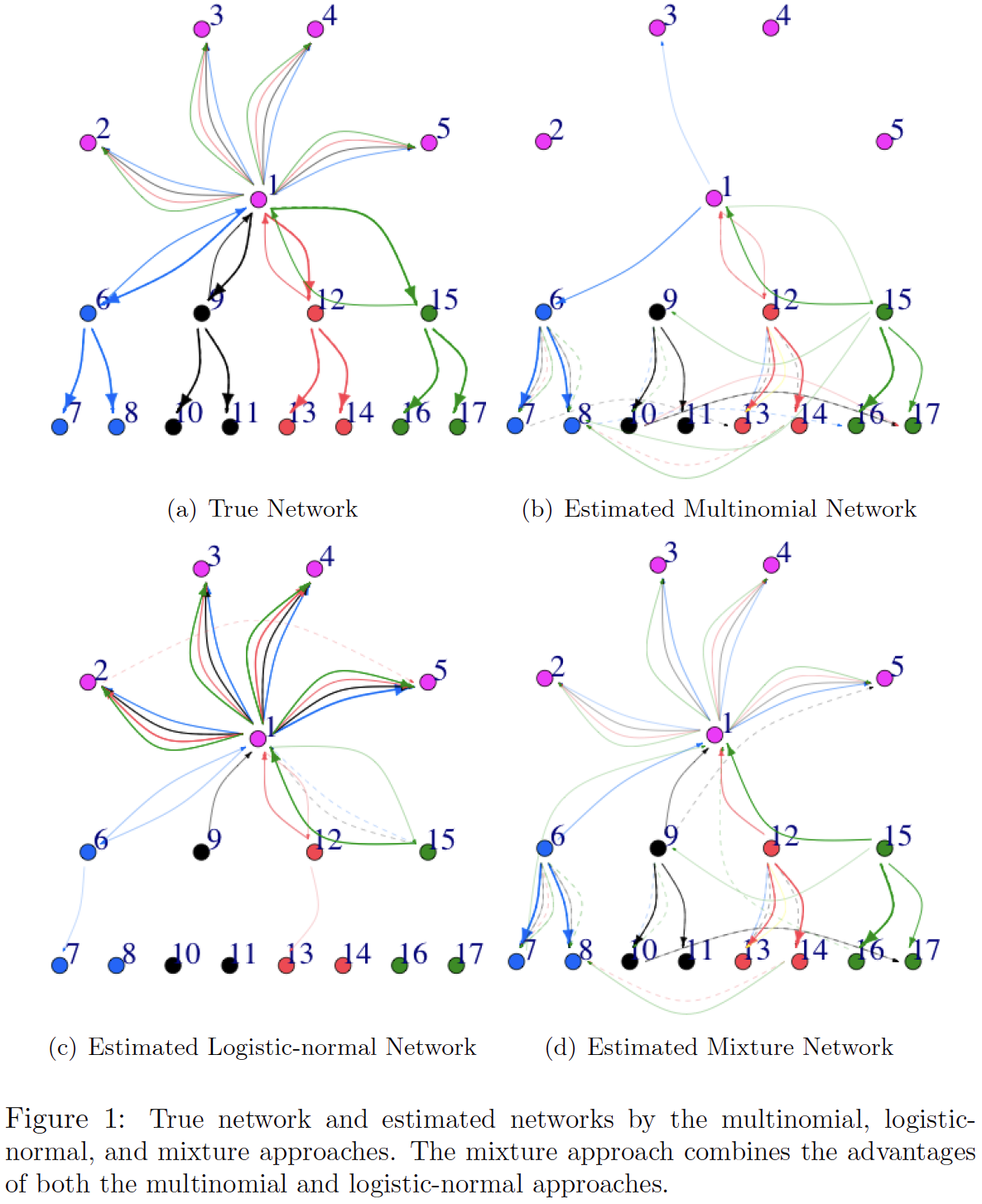
In this work, we propose two autoregressive models with corresponding methods and theory for learning context-dependent networks that reflect how features associated with an event (such as the content of a social media post) modulate the strength of influences among nodes. The multinomial approach we propose is suited to categorical marks and while the logistic-normal approach is suited to marks with mixed membership in different categories; a mixture approach is also proposed to combine the merits of both methods. The following figure provides a comparison among the three approaches.
Testing for high-dimensional network parameters in auto-regressive models
Lili Zheng, Garvesh Raskutti
Electronic Journal of Statistics. 2019 [Code]
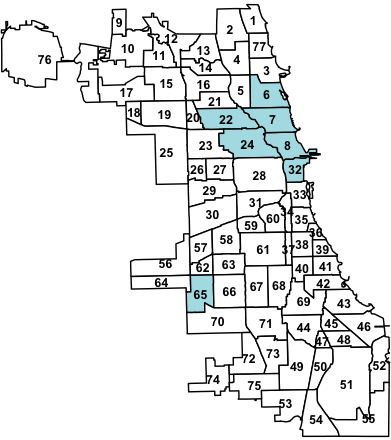
Below is an example of the hypothesis testing results of our method on Chicago crime data, where the goal is to test which community's past crimes has significant influence upon another community's future crimes. All communities involved in significant edges are colored, showing geographical approximity.
Tensor Data Analysis
Tensor data has attracted wide interest in recent years since it contains valuable high-order information, while its high-dimensionality imposes numerous statistical and computational challenges. One of my research interest is to develop efficient and statistically accurate algorithms for solving real-world tensor problems.
Papers:
Joint Semi-Symmetric Tensor PCA for Integrating Multi-modal Populations of Networks
Jiaming Liu*, Lili Zheng*, Zhengwu Zhang, Genevera I. Allen
Under revision
A Low-Rank Tensor Completion Approach for Imputing Functional Neuronal Data from Multiple Recordings
Lili Zheng; Zachary T. Rewolinski; Genevera I. Allen
IEEE Data Science and Learning Workshop (DSLW). 2022
Optimal High-order Tensor SVD via Tensor-Train Orthogonal Iteration
Yuchen Zhou, Anru R. Zhang, Lili Zheng, Yazhen Wang
IEEE Transactions on Information Theory. 2022 [Code]